本地模型配置
本地智能体(Local Agent)通过 YAML 配置文件进行管理。用户级配置文件路径如下:
- macOS / Linux:
~/.vjsp/config.yaml - Windows:
%USERPROFILE%\.vjsp\config.yaml
要编辑该文件,请在 IDE 聊天输入框右上角点击配置下拉菜单,选择 “Local Config” 旁的设置,即可打开 config.yaml。
智能体 = 模型(models) + 规则(rules) + 工具(MCP 服务器)
创建本地模型
在 IDE 中选择 本地智能体,点击其后的设置按钮,打开
config.yaml。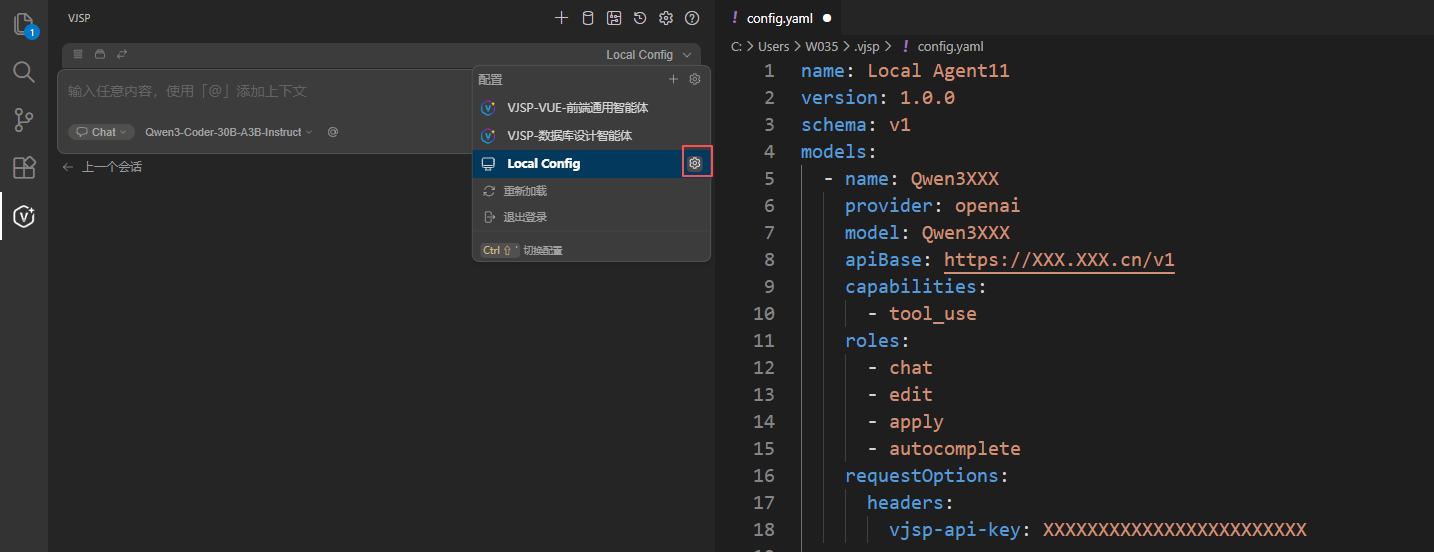
在文件中添加模型配置并保存,即可使配置生效。
- name: Qwen3-Coder-30B-A3B-Instruct
provider: openai
model: Qwen3-Coder-30B-A3B-Instruct
apiBase: http://www.example.com/v1
capabilities:
- tool_use
roles:
- chat
- edit
- apply配置文件顶层结构
以下为 config.yaml 中可配置的所有属性说明,除非明确标注为必填,否则所有层级的属性均为可选。
config.yaml 配置文件的顶层属性包括:
name: 我的配置 # 必填:配置名称
version: 1.0.0 # 必填:版本号
schema: v1 # 必填:配置架构版本
models: # 可选:模型定义
context: # 可选:上下文提供器
rules: # 可选:系统规则
prompts: # 可选:可调用提示词
docs: # 可选:文档站点索引
mcpServers: # 可选:MCP 工具服务器
data: # 可选:开发数据上报目标models
该部分用于定义配置中使用的语言模型。模型可实现对话、代码编辑、内容总结等功能。
属性说明:
name(必填):在配置内唯一标识该模型的名称。provider(必填):模型的提供者(例如openai)。model(必填):具体模型名称(例如Qwen3-Coder-30B-A3B-Instruct)。apiBase:可用于覆盖模型默认的基础 API 地址。roles:数组类型,指定模型可承担的角色,包括chat(对话)、autocomplete(自动补全)、embed(嵌入)、rerank(重排序)、edit(编辑)、apply(执行)。默认值为[chat, edit, apply]。capabilities:字符串数组,用于声明模型能力,会覆盖插件根据提供方和模型自动检测的能力。
tool_use:启用函数 / 工具调用能力(智能体模式必填)image_input:启用图片上传与处理能力多数模型的能力可由系统自动检测,若使用自定义部署或自动检测失效,可手动覆盖该配置
maxStopWords:允许的最大停止词(stop words)数量,避免因列表过长导致 API 错误。promptTemplates:可用于覆盖不同模型角色的默认提示词模板,支持的值包括chat、edit、apply和autocomplete。其中chat属性需填写有效的模板名称(如 llama3 或 anthropic)。chatOptions:若模型包含chat角色,以下设置适用于对话模式(Chat)和智能体模式(Agent):baseSystemMessage:可用于覆盖 对话模式 的默认系统提示词。basePlanSystemMessage:可用于覆盖 规划模式(Plan) 的默认系统提示词。baseAgentSystemMessage:可用于覆盖 智能体模式 的默认系统提示词。
embedOptions:若模型包含embed角色,以下设置适用于嵌入功能:maxChunkSize:单个文档块的最大 token 数,最小值为 128 token。maxBatchSize:单次请求可处理的最大数据块数量,最小值为 1 个。
defaultCompletionOptions:模型的默认生成配置:contextLength:模型的最大上下文长度(通常以 token 为单位)。maxTokens:单次生成内容时的最大 token 数。temperature:控制生成内容的随机性,取值范围为0.0(确定性)到1.0(随机性)。topP:核采样(nucleus sampling)的累积概率阈值。topK:每一步生成时考虑的最大 token 数量。stop:用于终止生成的停止词数组。
requestOptions:模型专属的 HTTP 请求配置:timeout:每次语言模型请求的超时时间。verifySsl:是否验证请求的 SSL 证书。caBundlePath:HTTP 请求所用自定义 CA 证书包的路径。proxy:HTTP 请求所用代理的 URL。headers:HTTP 请求的自定义头部信息。extraBodyProperties:需合并到 HTTP 请求体中的额外属性。noProxy:无需通过指定代理访问的主机名列表。clientCertificate:HTTP 请求所用客户端证书:cert:客户端证书文件的路径。key:客户端证书密钥文件的路径。passphrase:客户端证书密钥文件的可选密码。
autocompleteOptions:若模型包含autocomplete角色,以下设置适用于 Tab 自动补全功能:disable:布尔值,若为true,则禁用该模型的自动补全功能。maxPromptTokens:自动补全提示的最大 token 数。debounceDelay:触发自动补全前的延迟时间(以毫秒为单位)。modelTimeout:自动补全请求的模型超时时间(以毫秒为单位)。maxSuffixPercentage:提示词中分配给后缀(suffix)的最大百分比。prefixPercentage:输入内容中分配给前缀(prefix)的百分比。transform:布尔值,若为false,则禁用多行补全内容的裁剪,默认值为true。该配置对生成多行补全内容时无需转换即可获得更好效果的模型有用。template:自动补全的自定义模板(使用 Mustache 语法),可使用{{{ prefix }}}、{{{ suffix }}}、{{{ filename }}}、{{{ reponame }}} `和 `{{{ language }}} 变量。onlyMyCode:布尔值,若为 true,则仅将代码仓库内的代码纳入上下文。useCache:布尔值,若为 true,则启用补全内容的缓存功能。useImports:布尔值,若为 true,则将导入语句(imports)纳入上下文。useRecentlyEdited:布尔值,若为 true,则将最近编辑的文件纳入上下文。useRecentlyOpened:布尔值,若为 true,则将最近打开的文件纳入上下文。
示例:
name: 我的配置
version: 1.0.0
schema: v1
models:
- name: Qwen3-Coder-30B-A3B-Instruct
provider: openai
model: Qwen3-Coder-30B-A3B-Instruct
apiBase: http://www.example.com/v1
capabilities:
- tool_use
roles:
- chat
- edit
- apply
defaultCompletionOptions:
temperature: 0.7
maxTokens: 1500
- name: Qwen2-5-VL-32B-Instruct
provider: openai
model: Qwen2-5-VL-32B-Instruct
apiBase: http://www.example.com/v1
capabilities:
- tool_use
- image_input
roles:
- chat
- edit
- apply
defaultCompletionOptions:
temperature: 0.3context
该部分用于定义上下文提供器,为语言模型补充额外信息或上下文,每个提供器可配置专属参数。
属性说明:
provider(必填):上下文提供器的标识或名称(例如code、docs、web)。name:提供器的可选名称。params:用于配置提供器行为的可选参数。
示例:
name: 我的配置
version: 1.0.0
schema: v1
context:
- provider: file
- provider: code
- provider: diff
- provider: http
name: 上下文服务器
params:
url: "https://api.example.com/server"
- provider: terminalrules
规则(Rules)会被拼接至所有 智能体模式(Agent)、对话模式(Chat) 和 编辑模式(Edit) 请求的系统提示词中。
配置示例:
name: 我的配置
version: 1.0.0
schema: v1
rules:
- uses: sanity/sanity-opinionated # 存储于任务控制中心的规则文件
- uses: file://user/Desktop/rules.md # 本地存储的规则文件规则文件示例:
---
name: 语言风格规则(Pirate rule)
---
使用中文回答问题更多详情可参考 规则深度解析文档。
prompts
提示词(Prompts)可通过 / 命令调用。
配置示例:
name: 我的配置
version: 1.0.0
schema: v1
prompts:
- uses: supabase/create-functions # 存储于任务控制中心的提示词文件
- uses: file://user/Desktop/prompts.md # 本地存储的提示词文件提示词文件示例(prompts.md):
---
name: 生成中文注释
invokable: true
---
将当前文件中的所有注释重写为中文注释更多详情可参考 提示词深度解析文档。
docs
用于指定待索引的文档站点列表。
属性说明:
name(必填):文档站点的名称,会显示在下拉菜单等位置。startUrl(必填):爬虫的起始页面,通常为文档的根页面或介绍页面。favicon:站点图标的 URL,默认值为startUrl对应的/favicon.ico。useLocalCrawling:布尔值,若为true,则跳过默认爬虫,仅使用本地爬虫进行爬取。
示例:
name: 我的配置
version: 1.0.0
schema: v1
docs:
- name: VJSP 官方文档
startUrl: https://docs.VJSP.dev/intro
favicon: https://docs.VJSP.dev/favicon.icomcpServers
模型上下文协议(Model Context Protocol,MCP) 是 Anthropic 提出的标准,用于统一提示词、上下文和工具使用方式。通过 MCP 上下文提供器支持所有 MCP 服务器。
属性说明:
name(必填):MCP 服务器的名称。command(必填):用于启动服务器的命令。args:命令的可选参数数组。env:服务器进程的可选环境变量映射。cwd:执行命令的可选工作目录,支持绝对路径和相对路径。requestOptions:SSE和HTTP服务器的可选请求配置,格式与 模型的 requestOptions 一致。connectionTimeout:MCP 服务器初始连接的可选超时时间。
示例:
name: 我的配置
version: 1.0.0
schema: v1
mcpServers:
- name: 我的 MCP 服务器
command: uvx
args:
- mcp-server-sqlite
- --db-path
- ./test.db
cwd: /Users/NAME/project
env:
NODE_ENV: productiondata
用于配置开发数据的上报目标。
属性说明:
name(必填):数据目标的显示名称。destination(必填):接收数据的目标 / 端点,支持两种类型:HTTP 端点:会接收包含 JSON 数据的 POST 请求。
文件 URL:指向用于存储事件数据的目录,事件会以 .jsonl 文件格式存储。
schema(必填):待发送 JSON 数据的 schema 版本,可选值包括0.1.0和0.2.0。events:需包含的事件名称数组,若未指定则默认包含所有事件。level:事件字段的预定义过滤级别,可选值包括all(所有字段)和noCode(排除文件内容、提示词、生成结果等代码相关数据),默认值为all。apiKey:发送请求时使用的 API 密钥(通过 Bearer 头部传递)。requestOptions:事件 POST 请求的配置,格式与 模型的 requestOptions 一致。
示例:
name: 我的配置
version: 1.0.0
schema: v1
data:
- name: 本地数据仓库
destination: file:///Users/dallin/Documents/code/VJSPdev/VJSP-extras/external-data
schema: 0.2.0
level: all
- name: 企业私有数据端点
destination: https://mycompany.com/ingest
schema: 0.2.0
level: noCode
events:
- autocomplete完整 YAML 配置示例
以下为整合所有组件的完整 config.yaml 配置示例:
name: 我的配置
version: 1.0.0
schema: v1
models:
- name: Qwen3-Coder-30B-A3B-Instruct
provider: openai
model: Qwen3-Coder-30B-A3B-Instruct
roles:
- chat
- edit
defaultCompletionOptions:
temperature: 0.5
maxTokens: 2000
requestOptions:
headers:
Authorization: Bearer YOUR_OPENAI_API_KEY
- name: Qwen2-5-VL-32B-Instruct
provider: openai
model: Qwen2-5-VL-32B-Instruct
roles:
- autocomplete
autocompleteOptions:
debounceDelay: 350
maxPromptTokens: 1024
onlyMyCode: true
defaultCompletionOptions:
temperature: 0.3
stop:
- "\n"
rules:
- 回复需简洁明了
- 默认使用 TypeScript 而非 JavaScript
prompts:
- name: 单元测试生成
description: 为函数编写单元测试
prompt: |
请为该函数编写完整的单元测试套件,需使用 Jest 测试框架。
测试需覆盖所有可能的边缘场景,保证全面性,同时为每个测试用例添加说明。
- uses: myprofile/my-favorite-prompt
context:
- provider: diff
- provider: file
- provider: code
mcpServers:
- name: 开发服务器
command: npm
args:
- run
- dev
env:
PORT: "3000"
data:
- name: 企业私有数据端点
destination: https://mycompany.com/ingest
schema: 0.2.0
level: noCode
events:
- autocomplete
- chatInteraction利用 YAML 锚点避免配置重复
%YAML 1.1
---
name: 我的配置
version: 1.0.0
schema: v1
model_defaults: &model_defaults
provider: openai
apiKey: my-api-key
apiBase: https://api.example.com/llm
models:
- name: qwen2.5-coder-7b-instruct
<<: *model_defaults
model: qwen2.5-coder-7b-instruct
roles:
- chat
- edit
- name: qwen2.5-coder-7b
<<: *model_defaults
model: qwen2.5-coder-7b
useLegacyCompletionsEndpoint: false
roles:
- autocomplete
autocompleteOptions:
debounceDelay: 350
maxPromptTokens: 1024
onlyMyCode: true